Abstract
We introduce Motion Diversification Networks, a novel framework for learning to generate realistic and diverse 3D human motion. Despite recent advances in deep generative motion modeling, existing models often fail to produce samples that capture the full range of plausible and natural 3D human motion within a given context. The lack of diversity becomes even more apparent in applications where subtle and multi-modal 3D human forecasting is crucial for safety, such as robotics and autonomous driving. Towards more realistic and functional 3D motion models, we highlight limitations in existing generative modeling techniques, particularly in overly simplistic latent code sampling strategies. We then introduce a transformer-based diversification mechanism that learns to effectively guide sampling in the latent space. Our proposed attention-based module queries multiple stochastic samples to flexibly predict a diverse set of latent codes which can be subsequently decoded into motion samples. The proposed framework achieves state-of-the-art diversity and accuracy prediction performance across a range of benchmarks and settings, particularly when used to forecast intricate in-the-wild 3D human motion within complex urban environments.
Method
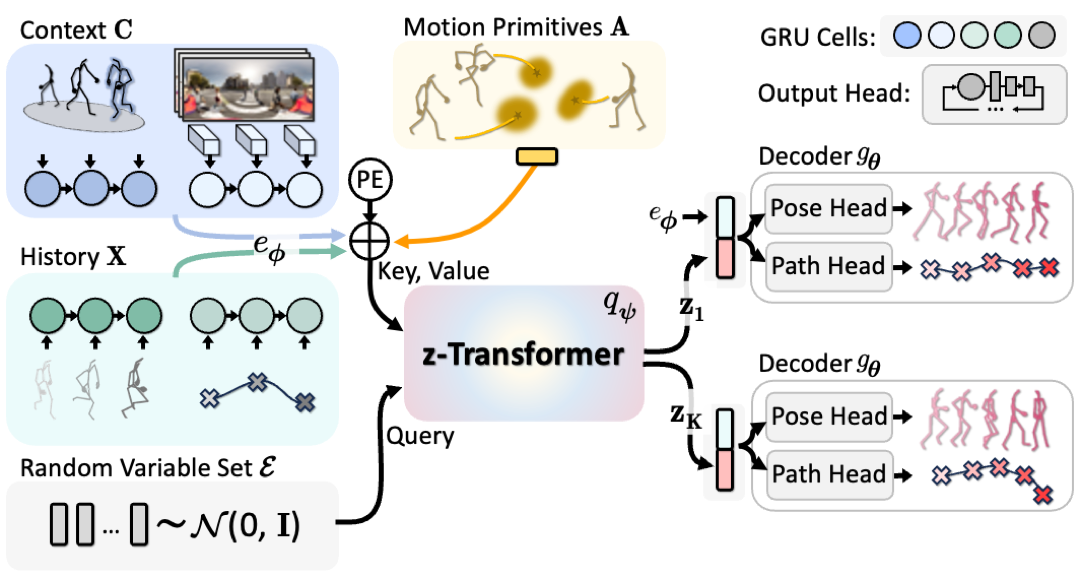
z-transformer: We employ an attention-based diversification module to produce a diverse set of latent vectors that expressively model correlations among multiple samples and modes.
Motion Primitives: To guide sample diversity and reduce modeling complexity in diverse scenarios, we incorporate deterministic motion primitives (centroids of clusters in the 3D pose space).
Scene and Social Context: We use the transformer architecture to easily fuse in additional context, i.e., as keys and values in the z-transformer.
Result
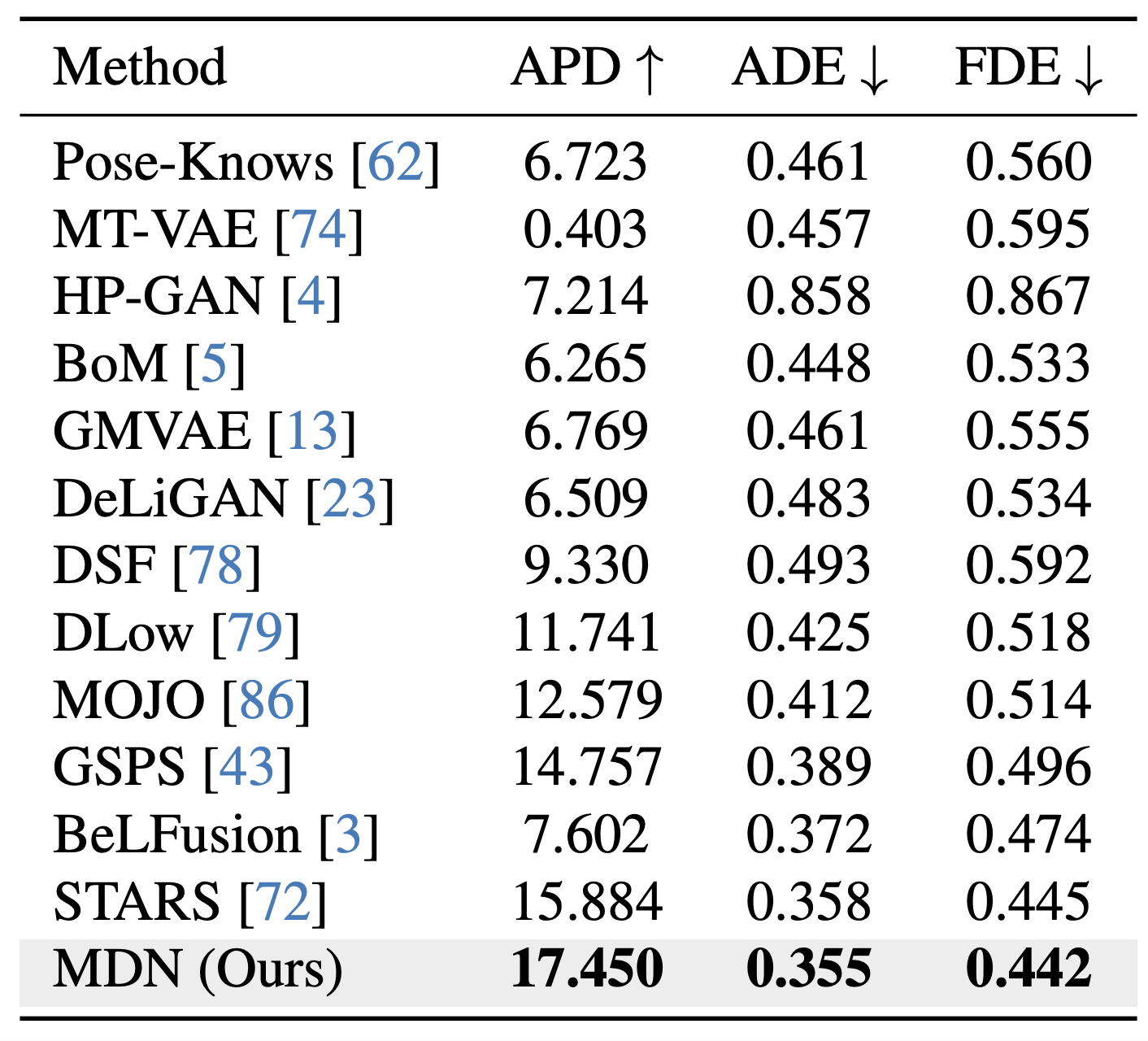
Evaluation on Human3.6M Our method achieves the best-known performance on the Human3.6M benchmark in terms of sample diversity without sacrificing prediction accuracy.
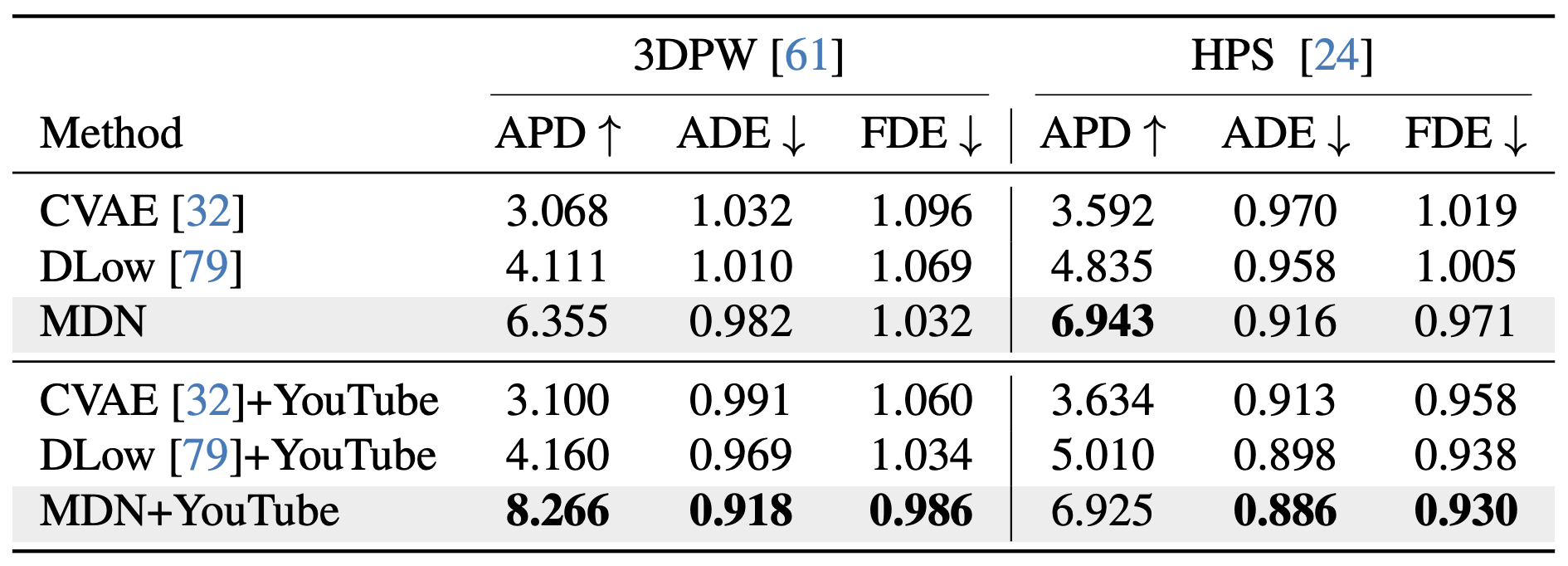
Evaluation on HPS and 3DPW Our model shows state-of-the-art results, in terms of diversity and accuracy, for two additional real-world benchmarks. Moreover, our model benefits from diverse data. Specifically, the addition of human motion trajectories extracted from in-the-wild videos (full details in our supplementary) is shown to further improve realism and diversity.
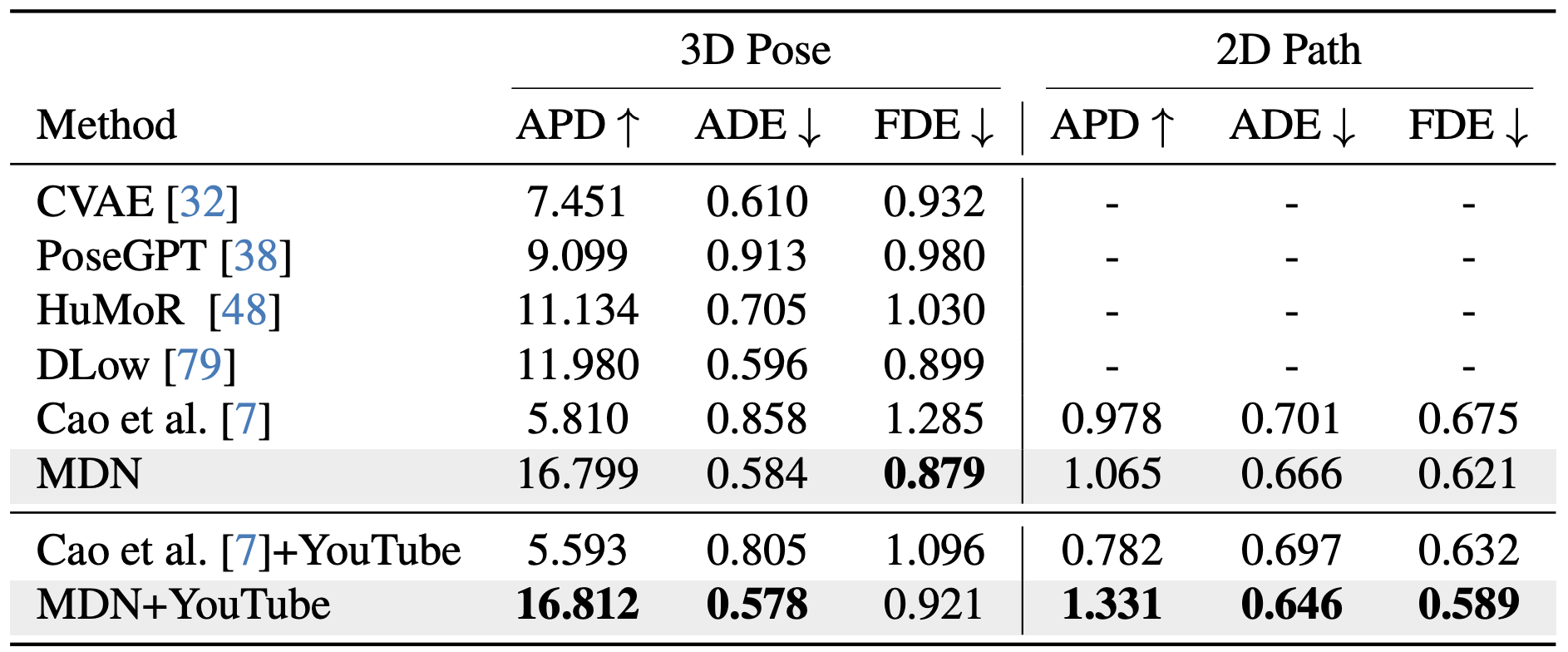
Evaluation on DenseCity Results are shown in terms of diversity (APD) and accuracy (ADE, FDE) against several baselines for both 3D pose and 2D trajectory error over a \textbf{two seconds future prediction} task.
Qualitative Results Visualization of the nuanced and diverse motion predicted by MDN. Specifically, we visualize how 2D paths predicted by our model are context-aware, effectively reasoning over scene layout (e.g., sidewalk or intersection) as well as subtle social interaction (e.g., at close proximity to surrounding pedestrians along the path).